Cache Hierarchy
A. Overview of Cache Hierarchy with Multiple Levels (L1, L2, L3)
Cache hierarchy consists of multiple cache levels, typically known as L1, L2, and L3 caches. Each cache level has a different capacity, access time, and proximity to the CPU.
L1 Cache: The closest cache to the CPU, consisting of separate instruction and data caches. It features the smallest capacity but the least latency. It stores frequently accessed data and instructions.
L2 Cache: The secondary cache with a larger capacity but higher latency, acts as a mediator between the L1 cache and the main memory. It stores additional data to reduce the need for main memory access.
L3 Cache: The highest cache level with the largest capacity and highest latency, it is typically shared among multiple cores or processors in a multi-core system.
B. Trade-offs between Cache Size, speed, and Proximity to CPU
Cache hierarchy involves trade-offs among cache size, speed, and proximity to the CPU.
Larger cache sizes can accommodate more data, and thereby raises the chances of cache hits and reduces cache misses. However, they also require more transistors and it leads to higher costs. Designers face the challenge of balancing cache size, cost, and expected benefits from improved performance. Different cache organizations, including direct-mapped, fully associative, or set-associative, have different trade-offs between capacity and access time.
Direct-mapped Cache: Each memory block maps to a specific cache location, resulting in simple hardware but potential conflicts.
Fully Associative Cache: Any memory block can be stored in any cache location, reducing conflicts but increasing hardware complexity and access time.
Set Associative Cache: The cache is divided into multiple sets and allows each memory block to be mapped to any location within its set. It strikes a balance between direct-mapped and fully associative caches. It reduces conflicts while maintaining lower access time compared to fully associative caches.
Caches located closer to the CPU, like the L1 cache, have lower latency and faster access time. As caches move further away from the CPU, such as the L2 and L3 caches, latency increases. This trade-off between speed and proximity is influenced by factors like cache organization, technology, and chip layout.
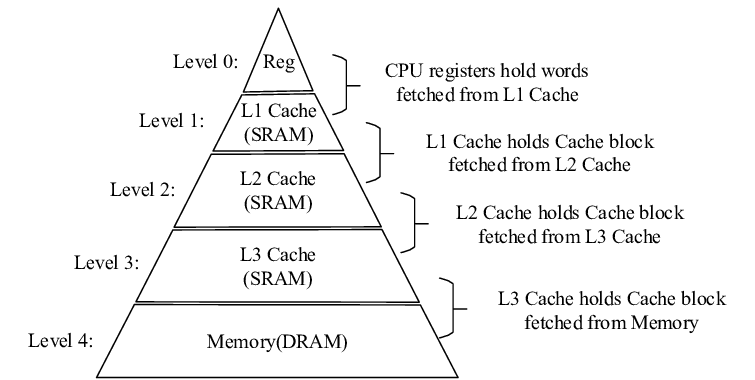
Larger cache sizes can accommodate more data, and thereby raises the chances of cache hits and reduces cache misses. However, they also require more transistors and it leads to higher costs. Designers face the challenge of balancing cache size, cost, and expected benefits from improved performance. Different cache organizations, including direct-mapped, fully associative, or set-associative, have different trade-offs between capacity and access time.
Caches located closer to the CPU, like the L1 cache, have lower latency and faster access time. As caches move further away from the CPU, such as the L2 and L3 caches, latency increases. This trade-off between speed and proximity is influenced by factors like cache organization, technology, and chip layout.
C. Retrieval process in Cache Hierarchy
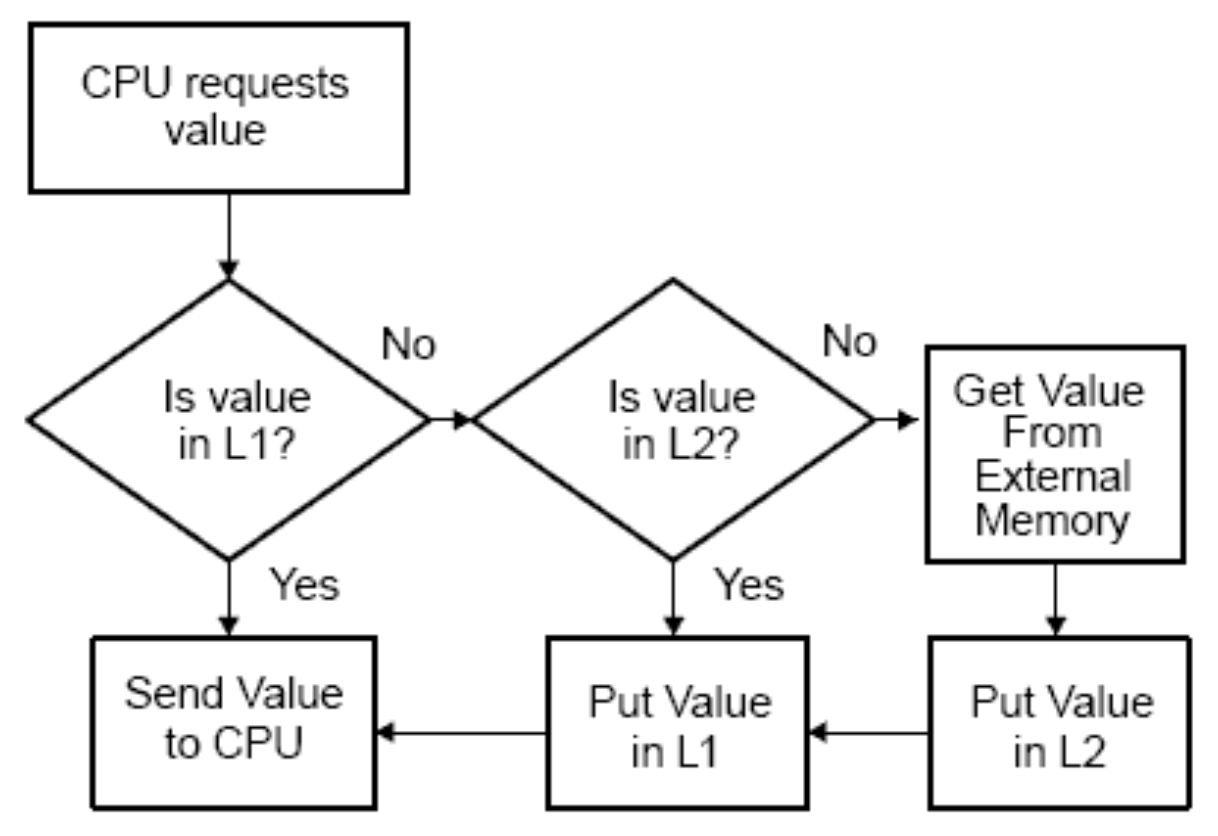
If data is not found in the L1 cache (cache miss), the CPU will check the larger but slower L2 cache. If the data is found in the L2 cache (cache hit), it will be fetched and sent to the CPU. This eliminates the need for main memory access.
If data is not found in the L2 cache (cache miss), the CPU will check the L3 cache or the main memory. The L3 cache, if available, acts as a larger shared cache for multiple cores. If the data is found in the L3 cache (cache hit), it will be retrieved and forwarded to the CPU.
If the data is absent in any cache level (cache miss), it has to be fetched from the main memory, resulting in a cache miss penalty. The cache hierarchy aims to exploit the principle of locality and minimize memory access. By keeping frequently accessed data in faster cache levels, the CPU significantly reduces data access times and enhances the system's performance.
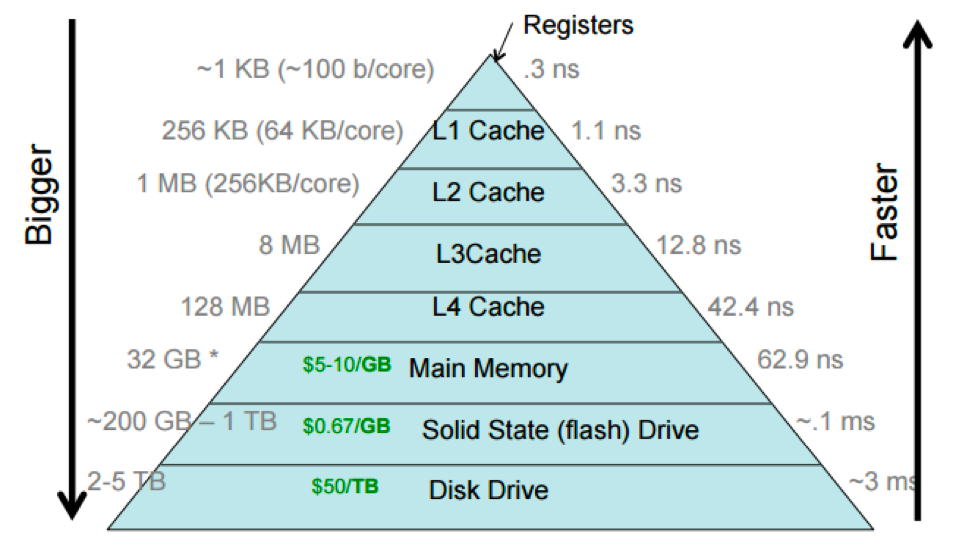
The cache hierarchy is designed in this way to exploit the principle of locality, which states that programs tend to access data and instructions that are spatially or temporally close to each other. By storing frequently accessed data in the smaller and faster cache levels, the CPU can significantly reduce the time required to access data and improve overall system performance.
By Lo Wing Sze (55678893)
Click to view the source code of this page.